





Cloudquery extracts the configuration and metadata of your infrastructure and transforms it into a relational SQL database. This allows you to write SQL queries for easy monitoring, governance, and security.
Key Features
Explore And Monitor With SQL
CloudQuery extracts, transforms (normalize), and loads (ETL) the data from scattered APIs across different cloud and SaaS providers into the PostgreSQL relational database. This gives you the ability to work with SQL to focus on your business logic without writing code and working directly with APIs.
Security And Compliance As Code
You can write your security and compliance rules using SQL as the query language and HCL as the engine. Just like you use IaC to build, change, and version your infrastructure, you can use CloudQuery Policies to monitor, alert, and version your cloud infrastructure security and compliance rules.
Extensible
CloudQuery is an open-source and extensible framework. All official and approved community providers and policies are listed in CloudQuery Hub. See Developing New Provider.
Use Cases
CloudQuery gives unprecedented power and visibility to your cloud infrastructure and SaaS applications in a normalized way that is accessible with SQL.
Below are a few well-known use cases for CloudQuery in security, DevOps, infra, and SRE teams.
Security And Compliance
CloudQuery Policies allow you to codify your security and compliance rules with SQL queries across cloud providers.
Cloud Inventory And Asset Management
CloudQuery Providers gives you the ability to gain visibility across accounts, different cloud providers, and SaaS applications.
CloudQuery gives you SQL access to your whole cloud environment.
Auditing
CloudQuery gives you the ability to monitor changes in your infrastructure over time, both for investigation and analysis purposes and for near real-time rules and alerts (available in CloudQuery SaaS.
Getting Started
Download and Install
You can download the precompiled binary from releases, or using CLI:
- Pre-Compiled Binaries
- Homebrew
- Docker
Download latest version:
export OS=Darwin # Possible values: Linux,Windows,Darwin
curl -L https://github.com/cloudquery/cloudquery/releases/latest/download/cloudquery_${OS}_x86_64 -o cloudquery
chmod a+x cloudquery
Download specific version:
export OS=Darwin # Possible values: Linux,Windows,Darwin
export VERSION= # specifiy a version
curl -L https://github.com/cloudquery/cloudquery/releases/download/${VERSION}/cloudquery_${OS}_x86_64 -o cloudquery
Running
All official and approved community providers are listed at CloudQuery Hub with their respective documentation.
Init Command
The first step is to generate a config.hcl file that will describe which cloud provider you want to use and which resources you want CloudQuery to ETL:
cloudquery init aws
cloudquery init gcp aws # This will generate a config containing gcp and aws providers
cloudquery init –help # Show all possible auto generated configs and flags
Spawn or Connect to a Database
CloudQuery needs a PostgreSQL database (>11). You can either spawn a local one (usually good for development and local testing) or connect to an existing one.
For local, you can use the following docker command:
docker run -p 5432:5432 -e POSTGRES_PASSWORD=pass -d postgres
If you are using an existing database, you will have to update the connection section in config.hcl:
cloudquery {
plugin_directory = “./cq/providers”
policy_directory = “./cq/policies”
provider “aws” {
source = “”
version = “latest”
}
connection {
dsn = “host=localhost user=postgres password=pass database=postgres port=5432”
}
}
Fetch Command
Once config.hcl is generated, run the following command to fetch the resources. (You need to be authenticated — see relevant section under each provider):
cloudquery fetch
#cloudquery fetch –help # Show all possible fetch flags
Once your provider has fetched resources, you can run the following example queries.
Exploring and Running Queries
Schema and tables for each provider are available in CloudQuery Hub
A few examples for AWS:
List ec2_images
SELECT * FROM aws_ec2_images;
Find all public-facing AWS load balancers:
SELECT * FROM aws_elbv2_load_balancers WHERE scheme = ‘internet-facing’;
Policy Command
CloudQuery Policies allow users to write security, governance, cost, and compliance rules, using SQL as the query layer and HCL as the logical layer.
All official and approved community policies are listed on CloudQuery Hub.
Execute a policy
All official policies are hosted at https://github.com/cloudquery-policies.
cloudquery policy run aws-cis-1.2.0
Fetch config.hcl
config.hcl is the main (and only) file needed for cloudquery to perform a fetch. As the suffix suggests, it uses the HCL language (See why).
In most cases, this file can be generated by cloudquery init [provider_name], and then you can just tweak the configuration if needed.
CloudQuery Block
The cloudquery block must be specified exactly once per config.hcl. This usually looks like:
// Configuration AutoGenerated by CloudQuery CLI
cloudquery {
plugin_directory = “./cq/providers”
policy_directory = “./cq/policies”
provider “aws” {
source = “”
version = “latest”
}
connection {
dsn = “host=localhost user=postgres password=pass database=postgres port=5432”
}
}
Arguments
- plugin_directory – directory where CloudQuery will download provider plugins.
- policy_directory – directory where CloudQuery will download policies.
Provider Block
This block must be specified one or more times, specifying which providers and which versions you want to use. All official and approved community providers are listed on CloudQuery Hub with their respective version and documentation.
The cloudquery fetch command will download all the providers with their respective version to plugin_directory. Once they are downloaded, CloudQuery will verify them and execute to ETL the configuration and metadata each provider supports.
Connection Block
The connection block specifies to which database you should connect via dsn argument.
Provider Block
The provider block must be specified one or more times, and should be first specified in the cloudquery block.
Each provider has two blocks:
configuration– The arguments are different from provider to provider and their documentation can be found in CloudQuery Hub.resources– All resources that this provider supports and can fetch configuration and meta-data from.
init
Generates initial config.hcl for fetch command.
Usage
cloudquery init [choose one or more providers (aws,gcp,azure,okta,…)] [flags]
Examples
#Downloads AWS provider and generates config.hcl for AWS provider
cloudquery init aws
#Downloads AWS, GCP providers and generates one config.hcl with both providers
cloudquery init aws gcp
Additional Help Topics
Use “cloudquery init options” for a list of global CLI options.
fetch
Fetches resources from configured providers.
This requires a config.hcl file which can be generated by cloudquery init.
Usage
cloudquery fetch [flags]
Examples
#Fetch configured providers to PostgreSQL as configured in config.hcl
cloudquery fetch
Additional Help Topics
Use “cloudquery fetch options” for a list of global CLI options.
Policy
Top-level command to download and execute CloudQuery Policies.
Usage
cloudquery policy [command]
Available Commands
download Download a policy from the CloudQuery Policy Hub
run Executes a policy on CloudQuery database
Additional Help Topics
Use “cloudquery policy [command] –help” for more information about a command.
Use “cloudquery policy options” for a list of global CLI options.
policy download
Download a policy from the CloudQuery Policy Hub.
Usage
cloudquery policy download GITHUB_REPO [flags]
Examples
Download official policy
cloudquery policy download aws-cis-1.2.0
The following will be the same as above
Official policies are hosted here: https://github.com/cloudquery-policies
cloudquery policy download cloudquery-policies/aws-cis-1.2.0
Download community policy
cloudquery policy download COMMUNITY_GITHUB_ORG/aws-cis-1.2.0
See https://hub.cloudquery.io for additional policies.
Additional Help Topics
Use “cloudquery policy download options” for a list of global CLI options.
policy run
Executes a policy on CloudQuery database.
Usage
cloudquery policy run GITHUB_REPO [PATH_IN_REPO] [flags]
Flags
-h, –help Help for run
–output string Generates a new file at the given path with the output
–skip-download Skips downloading the policy repository
–skip-versioning Skips policy versioning and uses latest files
–stop-on-failure Stops the execution on the first failure
–sub-path string Forces the policy run command to only execute this sub-policy/query
Additional Help Topics
Use “cloudquery policy run options” for a list of global CLI options.
Completion
Installs shell completion for CloudQuery CLI.
Usage
cloudquery completion [bash|zsh|fish|powershell]
Bash
$source <(cloudquery completion bash) To load completions for each session, execute once: Linux: cloudquery completion bash > /etc/bash_completion.d/cloudquery
MacOS:
$cloudquery completion bash > /usr/local/etc/bash_completion.d/cloudquery
Zsh
#If shell completion is not already enabled in your environment, you will need
#to enable it. You can execute the following once:
$echo “autoload -U compinit; compinit” >> ~/.zshrc
#To load completions for each session, execute once:
$cloudquery completion zsh > “${fpath[1]}/_cloudquery”
#You will need to start a new shell for this setup to take effect.
Fish
$cloudquery completion fish | source
#To load completions for each session, execute once:
$cloudquery completion fish > ~/.config/fish/completions/cloudquery.fish
Powershell
PS> cloudquery completion powershell | Out-String | Invoke-Expression
#To load completions for every new session, run:
PS> cloudquery completion powershell > cloudquery.ps1
#and source this file from your powershell profile.
Architecture
This is an advanced section describing the inner workings and design of CloudQuery. (It might be useful when developing new providers).
CloudQuery has a pluggable architecture and is using the go-plugin to load, run, and communicate between providers via gRPC. To develop a new provider for CloudQuery, you don’t need to understand the inner workings of go-plugin as those are abstracted away cq-provider-sdk.
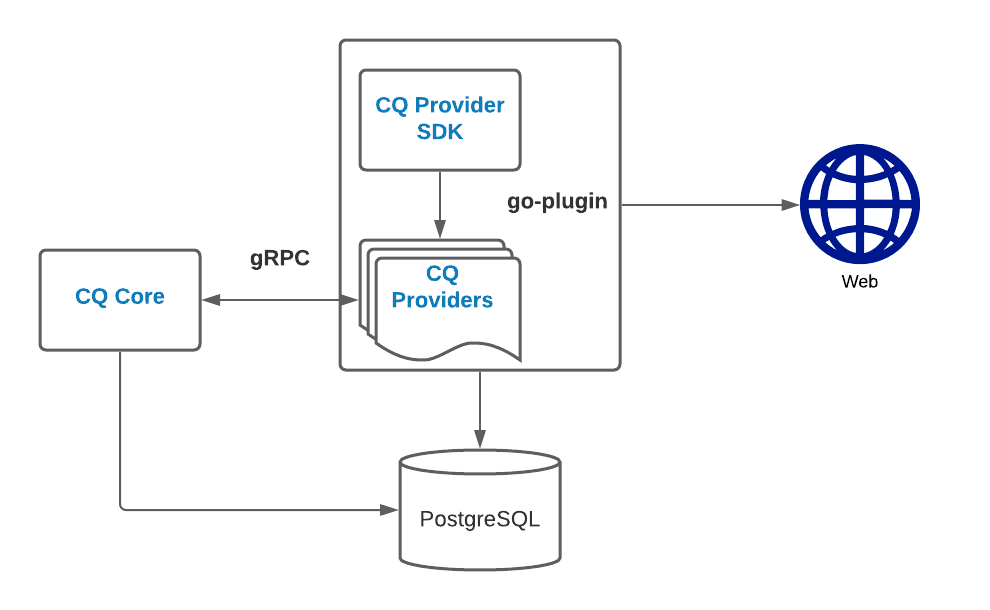
Similarly to any application utilizing the go-plugin framework, CloudQuery is split into CloudQuery Core and CloudQuery Providers.
CloudQuery Core Responsibilities
- Main entry point and CLI for the user.
- Reading CloudQuery configuration.
- Downloading, verifying, and running providers.
- Running policy packs.
CloudQuery Provider Responsibilities
- Intended to be run only by cloudquery-core.
- Communicates with cloudquery-core over gRPC to receive commands and actions.
- Initialization, authentication, and fetching data via third-party cloud/SaaS API.
Debugging
Running the provider in debug mode
Debugging CQ providers is a fairly straightforward process:
First, we must run the provider in debug mode. To do this, set the environment variable CQ_PROVIDER_DEBUG=1 in our IDE or terminal and execute the provider.
The following message will appear when executing the plugin binary.
Linux/Osx
Provider started, to attach Cloudquery set the CQ_REATTACH_PROVIDERS env var:
export CQ_REATTACH_PROVIDERS=/cq-my-provider/.cq_reattach
Windows
Provider started, to attach Cloudquery set the CQ_REATTACH_PROVIDERS env var:
Command Prompt: set CQ_REATTACH_PROVIDERS=./providers/cq-my-provider/.cq_reattach
PowerShell: $env:CQ_REATTACH_PROVIDERS=./providers/cq-my-provider/.cq_reattach
Once we set up CQ_REATTACH_PROVIDERS, we will be able to execute any command from our CQ binary and it will use the debugged plugin instead of the latest version.
Example
In the following example, we will download an existing provider, compile it, and execute it in debug mode.
git clone https://github.com/cloudquery/cq-provider-aws.git
go build -o cq-provider-aws
export CQ_PROVIDER_DEBUG=1
./cq-provider-aws // Execute the provider binary
// Provider started, to attach Cloudquery set the CQ_REATTACH_PROVIDERS env var:
// export CQ_REATTACH_PROVIDERS=//.cq_reattach
After executing the provider, we will get a message about how to reattach our provider when we execute the main CQ binary.
// Path where we executed our aws provider
export CQ_REATTACH_PROVIDERS=/providers/cq-provider-aws/.cq_reattach
./cloudquery fetch –dsn “host=localhost user=postgres password=pass DB.name=postgres port=5432”
Developing A New Provider
This section will go through what is needed to develop you own provider for CloudQuery and optionally publish it in on CloudQuery Hub.
Before continuing, it is recommended to get familiar with CloudQuery architecture.
CloudQuery providers utilize cq-provider-sdk, which abstracts most of the TL (in ETL, extract-transform-load). So, as a developer, you will only have to implement the (“E” in “ETL”) initializing, authentication, and fetching of the data via the third-party APIs — the SDK will take care of transforming the data and loading it into the database. Also, your provider will get support out-of-the-box for new features and things like other database support as cloudquery-core progress.
Here is a template project from which you can create your own https://github.com/cloudquery/cq-provider-template.
We will go through the files in the template and explain each part that you need to implement.
resources/provider.go
func Plugin() plugin.Provider { return &plugin.Provider{ Name: “your_provider_name”, Configure: provider.Configure, ResourceMap: map[string]schema.Table{
“resource_name”: resources.ResourceName(),
},
Config: func() provider.Config {
return &provider.Config{}
},
}
In this file, everything is already set up for you and you only need to change Name to match your provider name and add new resources to ResourceMap as you implement them and add them to your provider.
client/config.go
package client
// Provider Configuration
type Account struct {
Name string hcl:"name,optional"
}
type Config struct {
Account []Account hcl:"account,block"
User string hcl:"user,optional"
Debug bool hcl:"debug,optional"
}
// Pass example to cloudquery when cloudqueyr init will be called
func (c Config) Example() string {
return `configuration {
// Optional. create multiple blocks of accounts the provider will run
// account {
// name =
// }
// Optional. Some field we decided to add
user = “cloudquery”
// Optional. Enable Provider SDK debug logging.
debug = false
}
}
This function is called before fetching any resources. The provider has a chance to read the top-level configuration, init and authenticate all needed third-party clients, and return your initialized object that will be passed to each one of your fetchers.
resources/demo_resources.go
In this directory, you will create a new file for each resource. Each resource may contain one or more related tables. See documentation inline.
package resources
import (
“context”
“github.com/cloudquery/cq-provider-sdk/plugin/schema”
“github.com/cloudquery/cq-provider-template/client”
)
func DemoResource() *schema.Table {
return &schema.Table{
// Required. Table Name
Name: “provider_demo_resources”,
// Required. Fetch data for table. See fetchDemoResources
Resolver: fetchDemoResources,
// Optional. DeleteFilter returns a list of key/value pairs to add when truncating this table’s data from the database.
// DeleteFilter: nil, // func(meta ClientMeta) []interface{}
// Optional. Returns re-purposed meta clients. The SDK will execute the table with each of them. Useful if you want to execute for different accounts, etc…
// Multiplex: nil, // func(meta ClientMeta) []ClientMeta
// Optional. Checks if returned error from table resolver should be ignored. If it returns true, the SDK will ignore and continue instead of aborting.
// IgnoreError: nil, // IgnoreErrorFunc func(err error) bool
// Optional. Post resource resolver is called after all columns have been resolved, and before resource is inserted to database.
// PostResourceResolver: nil, // RowResolver func(ctx context.Context, meta ClientMeta, resource *Resource) error
Columns: []schema.Column{
{
Name: “account_id”,
Type: schema.TypeString,
// Optional. You can have a special column resolver if the column name doesn’t match the name or it’s just an additional
// column that needs to get the data from somewhere else.
Resolver: customColumnResolver,
},
{
Name: “region”,
Type: schema.TypeString,
},
{
Name: “creation_date”,
Type: schema.TypeTimestamp,
},
{
Name: “name”,
Type: schema.TypeString,
// schema.PathResolver is a utility function that gets the data from a different name in the struct.
// Resolver: schema.PathResolver(“other_name_in_struct”),
},
},
// A table can have relations
//Relations: []*schema.Table{
// {
// Name: “provider_demo_resource_children”,
// Resolver: fetchDemoResourceChildren,
// Columns: []schema.Column{
// {
// Name: “bucket_id”,
// Type: schema.TypeUUID,
// Resolver: schema.ParentIdResolver,
// },
// {
// Name: “resource_id”,
// Type: schema.TypeString,
// Resolver: schema.PathResolver(“Grantee.ID”),
// },
// {
// Name: “type”,
// Type: schema.TypeString,
// Resolver: schema.PathResolver(“Grantee.Type”),
// },
// },
// },
//},
}
}
// ====================================================================================================================
// Table Resolver Functions
// ====================================================================================================================
func fetchDemoResources(ctx context.Context, meta schema.ClientMeta, parent *schema.Resource, res chan interface{}) error {
c := meta.(*client.Client)
_ = c
// Fetch using the third party client and put the result in res
// res <- c.ThirdPartyClient.getDat()
return nil
}
func customColumnResolver(ctx context.Context, meta schema.ClientMeta, resource *schema.Resource, c schema.Column) error {
resource.Set(“column_name”, “value”)
return nil
}
Essentially, for each resource that you support, you just need to define two things:
- The schema – how the table will look in the database – column names and types.
- Implement the main table resolver function that will fetch the data from the third-party SDK and pass it to the SDK.
- The SDK will automatically read the data and insert it into the table column using a default naming convention. The default naming convention is to CamelCase; in other words, if a column-name is
some_name, the field name in the struct that you pass to the SDK should be:SomeName. If you want a different name or logic, you can implement a column resolver.
- The SDK will automatically read the data and insert it into the table column using a default naming convention. The default naming convention is to CamelCase; in other words, if a column-name is
Best Practices
Read-Only Access to Cloud Providers
Each provider has its own way of authenticating (which is described in the hub), but a rule of thumb for all of them is that in 100% (if possible, of course) of the cases, CloudQuery requires only a read-only key to fetch the information. CloudQuery does not make any changes to your infrastructure or SaaS applications.
Cross-Account Access
If possible, you should use one read-only account per cloud provider that has access to all your accounts/projects. For example, in AWS, you can use the AssumeRole capability. In GCP, an account should be able to access all relevant projects (read-only). See the appropriate documentation on that in CloudQuery Hub.
If this is not possible, you can use multiple accounts by specifying multiple provider blocks.
Daily Infrastructure Snapshot
It is advised to run cloudquery fetch via cron on a daily basis (on lambda or any other secure place that has access to the required infrastructure). This, of course, varies highly depending on your needs, and can run even more frequently.
Security
This section will list key security points regarding CloudQuery. Make sure you follow best practices if you decide to “host it yourself.”
Security Provider Authentication Credentials
- Provider Authentication Credentials should always be read-only.
- The machine where CloudQuery is running should be secured with the correct permissions, as it contains the credentials to your cloud infrastructure.
Security CloudQuery Database
Even though the CloudQuery database contains only configuration and meta-data, you should protect it and keep it secure with correct access and permissions.




.png "Gshell : A Flexible And Scalable Cross-Plaform Shell Generator Tool")


{kind=link}