





Eyeballer is meant for large-scope network penetration tests where you need to find “interesting” targets from a huge set of web-based hosts. Go ahead and use your favorite screenshotting tool like normal (EyeWitness or GoWitness) and then run them through Eyeballer to tell you what’s likely to contain vulnerabilities, and what isn’t.
Example Labels
Old-Looking Sites
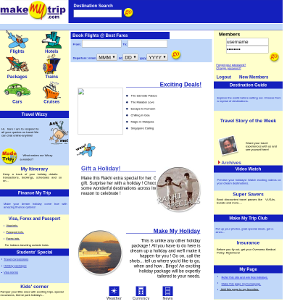
Login Pages
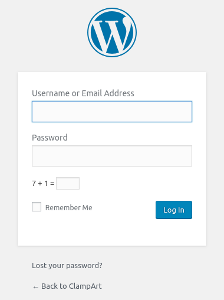
Webapp

Custom 404’s

Parked Domains
What The Labels Mean
Old-Looking Sites Blocky frames, broken CSS, that certain “je ne sais quoi” of a website that looks like it was designed in the early 2000’s. You know it when you see it. Old websites aren’t just ugly, they’re also typically super vulnerable. When you’re looking to hack into something, these websites are a gold mine.
Login Pages Login pages are valuable to pen testing, they indicate that there’s additional functionality you don’t currently have access to. It also means there’s a simple follow-up process of credential enumeration attacks. You might think that you can set a simple heuristic to find login pages, but in practice it’s really hard. Modern sites don’t just use a simple input tag we can grep for.
Webapp This tells you that there is a larger group of pages and functionality available here that can serve as surface area to attack. This is in contrast to a simple login page, with no other functionality. Or a default IIS landing page which has no other functionality. This label should indicate to you that there is a web application here to attack.
Custom 404 Modern sites love to have cutesy custom 404 pages with pictures of broken robots or sad looking dogs. Unfortunately, they also love to return HTTP 200 response codes while they do it. More often, the “404” page doesn’t even contain the text “404” in it. These pages are typically uninteresting, despite having a lot going on visually, and Eyeballer can help you sift them out.
Parked Domains Parked domains are websites that look real, but aren’t valid attack surface. They’re stand-in pages, usually devoid of any real functionality, consist almost entirely of ads, and are usually not run by our actual target. It’s what you get when the domain specified is wrong or lapsed. Finding these pages and removing them from scope is really valuable over time.
Setup
Download required packages on pip:
sudo pip3 install -r requirements.txt
Or if you want GPU support:
sudo pip3 install -r requirements-gpu.txt
NOTE: Setting up a GPU for use with TensorFlow is way beyond the scope of this README. There’s hardware compatibility to consider, drivers to install… There’s a lot. So you’re just going to have to figure this part out on your own if you want a GPU. But at least from a Python package perspective, the above requirements file has you covered.
Pretrained Weights
For the latest pretrained weights, check out the releases here on GitHub.
Training Data You can find our training data here:
https://www.dropbox.com/s/rpylhiv2g0kokts/eyeballer-3.0.zip?dl=1
There’s two things you need from the training data:
images/folder, containing all the screenshots (resized down to 224×224)labels.csvthat has all the labelsbishop-fox-pretrained-v3.h5A pretrained weights file you can use right out of the box without training.
Copy all three into the root of the Eyeballer code tree.
Predicting Labels
NOTE: For best results, make sure you screenshot your websites in a native 1.6x aspect ratio. IE: 1440×900. Eyeballer will scale the image down automatically to the right size for you, but if it’s the wrong aspect ratio then it will squish in a way that will affect prediction performance.
To eyeball some screenshots, just run the “predict” mode:
eyeballer.py –weights YOUR_WEIGHTS.h5 predict YOUR_FILE.png
Or for a whole directory of files:
eyeballer.py –weights YOUR_WEIGHTS.h5 predict PATH_TO/YOUR_FILES/
Eyeballer will spit the results back to you in human readable format (a results.html file so you can browse it easily) and machine readable format (a results.csv file).
Performance
Eyeballer’s performance is measured against an evaluation dataset, which is 20% of the overall screenshots chosen at random. Since these screenshots are never used in training, they can be an effective way to see how well the model is performing. Here are the latest results:
| Overall Binary Accuracy | 93.52% |
|---|---|
| All-or-Nothing Accuracy | 76.09% |
Overall Binary Accuracy is probably what you think of as the model’s “accuracy”. It’s the chance, given any single label, that it is correct.
All-or-Nothing Accuracy is more strict. For this, we consider all of an image’s labels and consider it a failure if ANY label is wrong. This accuracy rating is the chance that the model correctly predicts all labels for any given image.
| Label | Precision | Recall |
|---|---|---|
| Custom 404 | 80.20% | 91.01% |
| Login Page | 86.41% | 88.47% |
| Webapp | 95.32% | 96.83% |
| Old Looking | 91.70% | 62.20% |
| Parked Domain | 70.99% | 66.43% |
For a detailed explanation on Precision vs Recall, check out Wikipedia.
Training
To train a new model, run:
eyeballer.py train
You’ll want a machine with a good GPU for this to run in a reasonable amount of time. Setting that up is outside the scope of this readme, however.
This will output a new model file (weights.h5 by default).
Evaluation
You just trained a new model, cool! Let’s see how well it performs against some images it’s never seen before, across a variety of metrics:
eyeballer.py –weights YOUR_WEIGHTS.h5 evaluate
The output will describe the model’s accuracy in both recall and precision for each of the program’s labels. (Including “none of the above” as a pseudo-label)







{kind=link}