





Chomp-Scan is a scripted pipeline of tools to simplify the bug bounty/penetration test reconnaissance phase, so you can focus on chomping bugs.
Chomp Scan is a Bash script that chains together the fastest and most effective tools (in my opinion/experience) for doing the long and sometimes tedious process of recon.
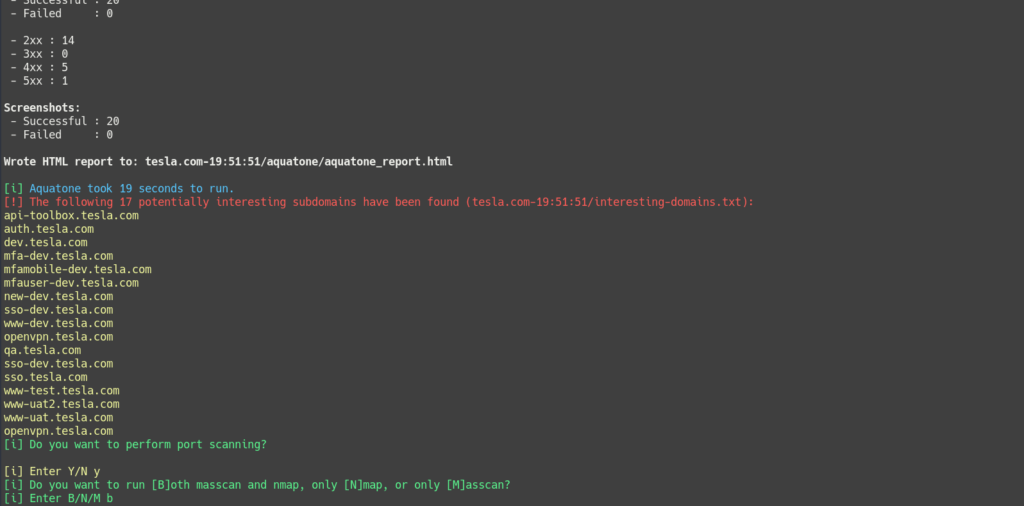
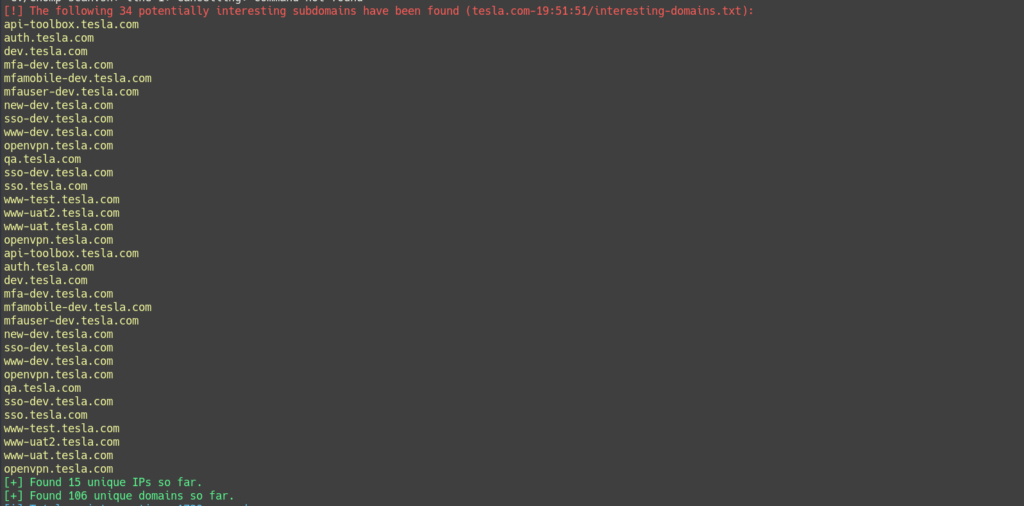
No more looking for word lists and trying to remember when you started a scan and where the output is. Chomp Scan can focus on a list of potentially interesting subdomains, letting you save time and focus on high-value targets. It can even notify you via Notica when it’s done running!
New Chomp Scan now integrates Notica, which allows you to receive a notification when the script finishes. Simply visit Notica and get a unique URL parameter, e.g. notica.us/?xxxxxxxx.
Pass the parameter to Chomp Scan via the -n flag, keep the Notica page open in a browser tab on your computer or phone, and you will receive a message when Chomp Scan has finished running. No more constantly checking/forgetting to check those long running scans.
A list of interesting words is included, such as dev, test, uat, staging,
etc., and domains containing those terms are flagged. This way you can
focus on the interesting domains first if you wish. This list can be
customized to suit your own needs, or replaced with a different file via
the -X flag.
Chomp Scan runs in multiple modes. A new Configuration File is the recommended way to run scans, as it allows the most granular control of tools and settings.
A standard CLI mode is included, which functions the same as any other CLI tool. A guided interactive mode is available, as well as a non-interactive mode, useful if you do not want to lookup parameters or worry about setting multiple arguments.
Also Read : Cuteit – IP Obfuscator Made to Make a Malicious IP a Bit Cuter
Configuration File
Chomp Scan now features a configuration file option that provides
more granular control over which tools are run and is less cumbersome
than passing a large number of CLI arguments. It can be used by passing
the -L flag. An example config file is included in this repo as a template, and complete config file details are available at the Configuration File wiki page.
Wordlists
A variety of wordlists are used, both for subdomain bruteforcing and content discovery. Daniel Miessler’s Seclists are used heavily, as well as Jason Haddix’s lists. Different wordlists can be used by passing in a custom wordlist or using one of the built-in named argument lists. See the Wordlist wiki page for more details.
Installation
Clone this repo and run the included installer.sh script. Make sure to run source ~/.profile in your terminal after running the installer in order to add the Go binary path to your $PATH variable.
Then run Chomp Scan. If you are using zsh, fish, or some other shell, make sure that ~/go/bin is in your path. For more details, see the Installation wiki page.
Usage
Chomp Scan always runs subdomain enumeration, thus a domain is required via the -u
flag. The domain should not contain a scheme, e.g. http:// or https://.
By default, HTTPS is always used. This can be changed to HTTP by
passing the -H flag. A wordlist is optional, and if one is not provided the built-in short list (20k words) is used.
Other scan phases are optional. Content discovery can take an optional wordlist, otherwise it defaults to the built-in short (22k words) list.
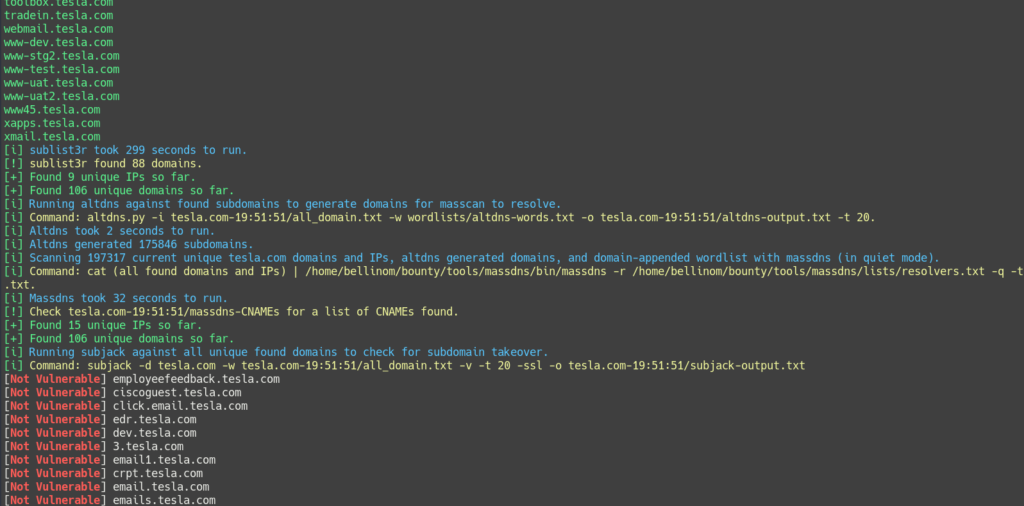
The final results of the scan are stored in three text files in the output directory. All unique domains that are found, whether they resolve or not, are stored in all_discovered_domains.txt, and all unique IPs that are discovered are stored in all_discovered_ips.txt.
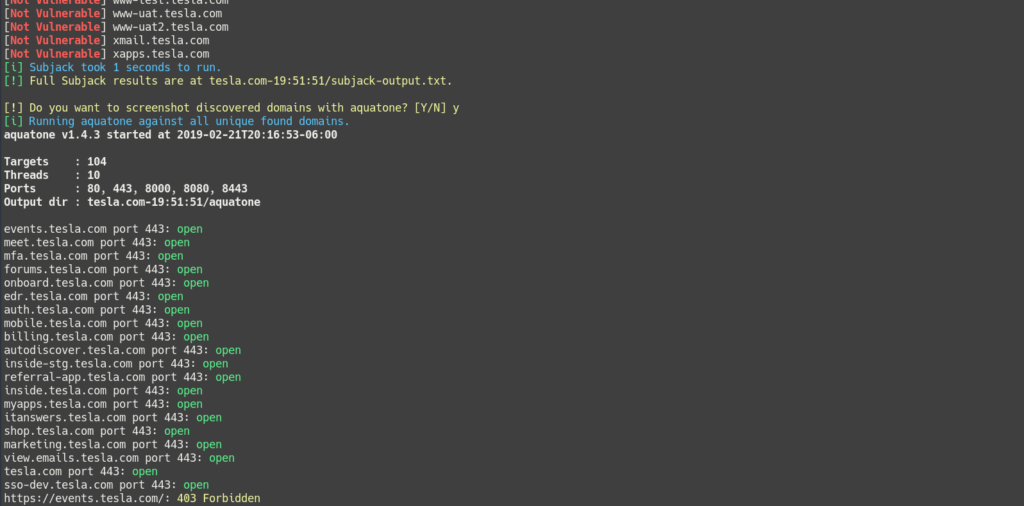
All domains that resolve to an IP are stored in all_resolved_domains.txt. As of v4.1 these domains are used to generate the interesting domain list and the all domains list, which can then be used for content discovery and information gathering.
chomp-scan.sh -u example.com -a d short -cC large -p -o path/to/directory
Usage of Chomp Scan:
-u domain
(required) Domain name to scan. This should not include a scheme, e.g. https:// or http://.
-L config-file
(optional) The path to a config file. This can be used to provide more granular control over what tools are run.
-d wordlist
(optional) The wordlist to use for subdomain enumeration. Three built-in lists, short, long, and huge can be used, as well as the path to a custom wordlist. The default is short.
-c
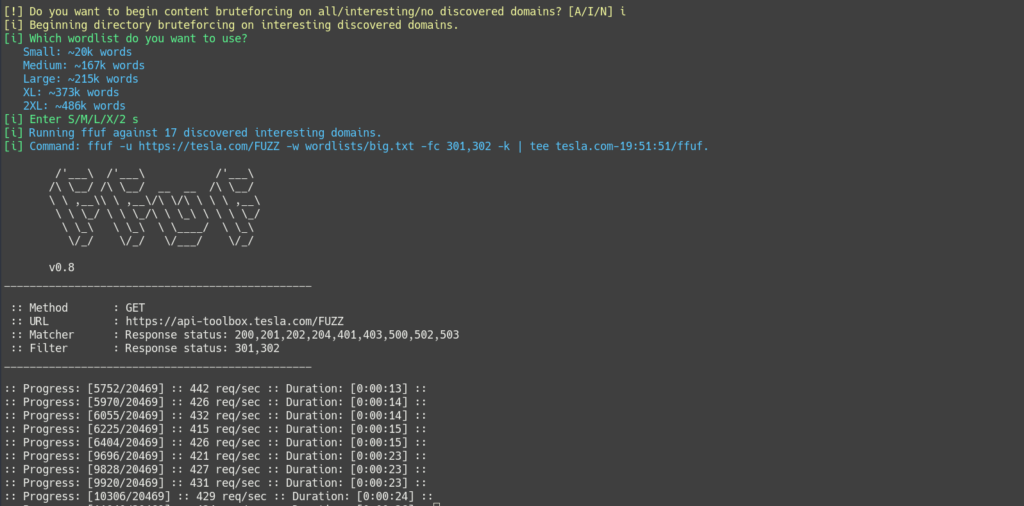
(optional) Enable content discovery phase. The wordlist for this option defaults to short if not provided.
-C wordlist
(optional) The wordlist to use for content discovery. Five built-in lists, small, medium, large, xl, and xxl can be used, as well as the path to a custom wordlist. The default is small.
-s
(optional) Enable screenshots using Aquatone.
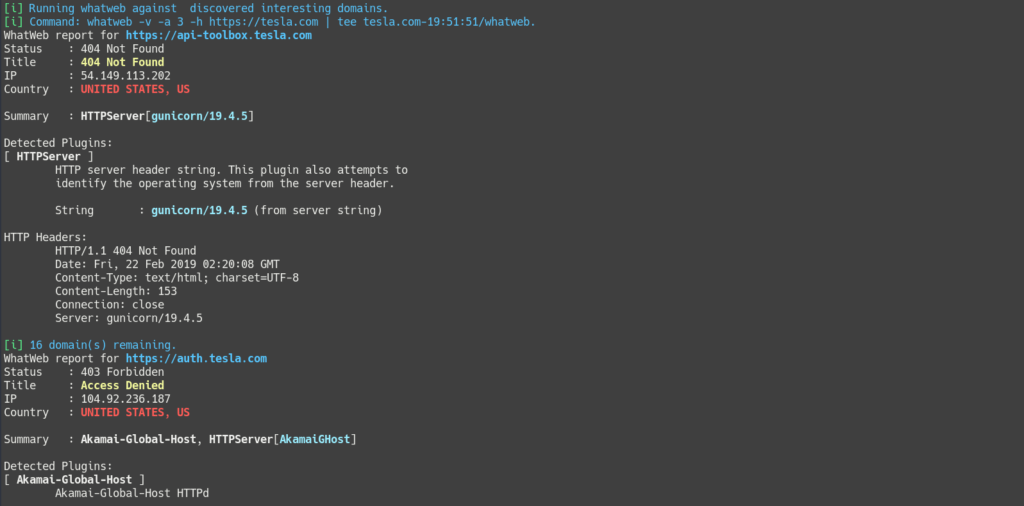
-i
(optional) Enable information gathering phase, using subjack, CORStest, S3Scanner, bfac, whatweb, wafw00f, and nikto.
-p
(optional) Enable portscanning phase, using masscan (run as root) and nmap.
-I
(optional) Enable interactive mode. This allows you to select certain tool options and inputs interactively. This cannot be run with -D.
-D
(optional) Enable default non-interactive mode. This mode uses pre-selected defaults and requires no user interaction or options. This cannot be run with -I.
Options: Subdomain enumeration wordlist: short.
Content discovery wordlist: small.
Aquatone screenshots: yes.
Portscanning: yes.
Information gathering: yes.
Domains to scan: all unique discovered.
-b wordlist
(optional) Set custom domain blacklist file.
-X wordlist
(optional) Set custom interesting word list.
-o directory
(optional) Set custom output directory. It must exist and be writable.
-a
(optional) Use all unique discovered domains for scans, rather than interesting domains. This cannot be used with -A.
-A
(optional, default) Use only interesting discovered domains for scans, rather than all discovered domains. This cannot be used with -a.
-H
(optional) Use HTTP for connecting to sites instead of HTTPS.
-h
(optional) Display this help page.
In The Future
Chomp Scan is still in active development, as I use it myself for bug hunting, so I intend to continue adding new features and tools as I come across them. New tool suggestions, feedback, and pull requests are all welcomed. Possible additions:
- The generation of an HTML report, similar to what aquatone provides
Screenshots






.png "Mangle : Tool That Manipulates Aspects Of Compiled Executables (.Exe Or DLL) To Avoid Detection From EDRs")