






Duplicut is a modern password wordlist creation usually implies concatenating multiple data sources.
Ideally, most probable passwords should stand at start of the wordlist, so most common passwords are cracked instantly.
With existing dedupe tools you are forced to choose if you prefer to preserve the order OR handle massive wordlists.
Unfortunately, wordlist creation requires both:

So i wrote duplicut in highly optimized C to address this very specific need
Quick start
git clone https://github.com/nil0x42/duplicut
cd duplicut/ && make
./duplicut wordlist.txt -o clean-wordlist.txt
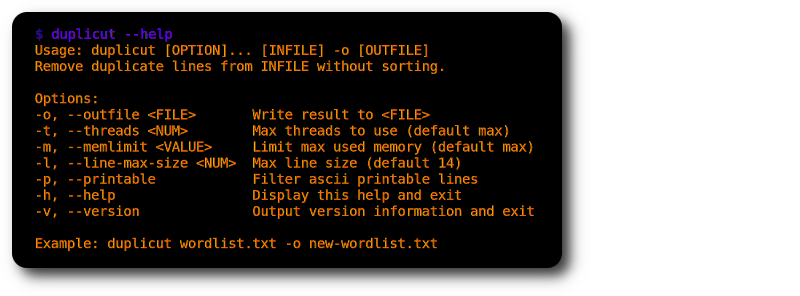
Options
Features
- Handle massive wordlists, even those whose size exceeds available RAM
- Filter lines by max length (
-loption) - Can remove lines containing non-printable ASCII chars (
-poption) - Press any key to show program status at runtime.
Implementation
- Written in pure C code, designed to be fast
- Compressed hashmap items on 64 bit platforms
- Multithreading support
- [TODO]: Use huge memory pages to increase performance
Limitations
- Any line longer than 255 chars is ignored
- Heavily tested on Linux x64, mostly untested on other platforms.
Technical Details
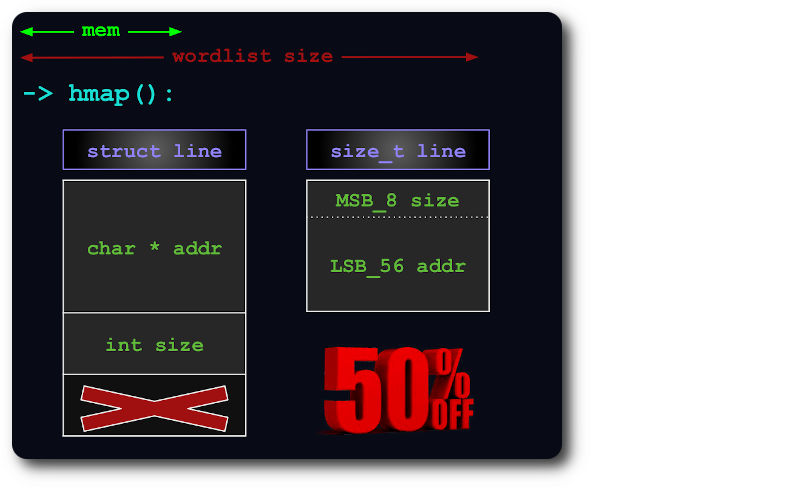
1- Memory optimized
An uint64 is enough to index lines in hashmap, by packing size info within pointer’s extra bits:
2- Massive file handling
If whole file can’t fit in memory, it is split into virtual chunks, then each one is tested against next chunks.
So complexity is equal to th triangle number:

Throubleshotting
If you find a bug, or something doesn’t work as expected, please compile duplicut in debug mode and post an issue with attached output:






{kind=link}